
In diesem Blogeintrag werden Methoden der funktionalen Datenanalyse angewandt um den Zugspitz Ultratrail 2014 statistisch zu analysieren. Das Maß aller Läufer ist dabei Stephan Hugenschmidt, der den Lauf außer Konkurrenz absolvierte.
Während der Fokus der letzten Monate von Outdooraktivitäten auf Indoorarbeit rückte, ist es lange Zeit auf dem Blog ruhig geblieben. Die Weihnachtstage wollte ich dann jedoch einmal für etwas nutzen, was ich bereits seit dem Sommer plante: eine Verknüpfung von Arbeit und Sport in Form einer statistischen Analyse des Zugspitz Ultratrails 2014.
Steve hat auf seinem Blog www.uptothetop.de in einem sehr lesenswerten Artikel bereits die wichtigsten Kennzahlen zu den Zugspitz Ultratrails der letzten 4 Jahre zusammengetragen. Dabei lag sein Fokus insbesondere auf der Zusammenfassung der Entwicklung der Siegerzeiten, Geschlechter- sowie Abbrecherquoten und die Fragestellung, ob man die Cut-Off Zeiten der Veranstaltung anpassen sollte. Ich möchte mich hier ausschließlich mit der letzten Ausgabe des Zugspitz Ultratrails 2014 beschäftigen. Die dafür verwendeten Daten sind öffentlich auf www.datasport.com zugänglich.
Zusammenfassung der Daten
Im Jahr 2014 gingen insgesamt 680 Ultratrailer an der Start: 619 Männer und 61 Frauen. Insgesamt erreichten davon lediglich 493 oder 72.5% der Athleten das Ziel. Die Finisherzahl teilt sich dabei auf 446 männliche und 47 weibliche Athleten auf. Die Zusammenfassung der gesamten Finisherzeiten (in hh:mm:ss) des Ultratrails können wir der nachfolgenden Tabelle entnehmen:
| Min. | 1. Quartil | Median | ∅ | 3. Quartil | Max. |
|---|---|---|---|---|---|
| 10:36:50h | 16:52:08h | 19:19:03h | 19:24:10h | 22:13:33h | 25:35:45h |
Während Stephan Hugenschmidt mit einer neuen Rekordzeit von 10:36 Stunden in das Ziel einlief, gehörte man mit ca. 16 Stunden und 52 Minuten noch zu den top 25% der Finisher. Der durchschnittliche Läufer benötigte hingegen mit 19:24 Stunden lediglich 2.5 Stunden mehr und legte damit eine Zeit zurück, die nur knapp über der Zeit des Medianläufers lag. Der letzte Finisher brauchte hingegen mit 25:35 Stunden etwas mehr als einen Tag um die etwa 100 km lange Strecke zu bewältigen.
Auffallend ist, dass die Finisherzeiten der mittleren 50% der Läufer um lediglich insgesamt 5:20 Stunden auseinander liegen, was auf einer solchen Distanz doch noch als relativ eng angesehen werden kann und für den außerordentlich guten allgemeinen Trainingszustand der Finisher spricht.
Etappenzeiten der männlichen und weiblichen Teilnehmer
Der folgende Boxplot trennt die Etappenzeiten sämtlicher Teilnehmer in die Gruppe der Frauen und Männer.
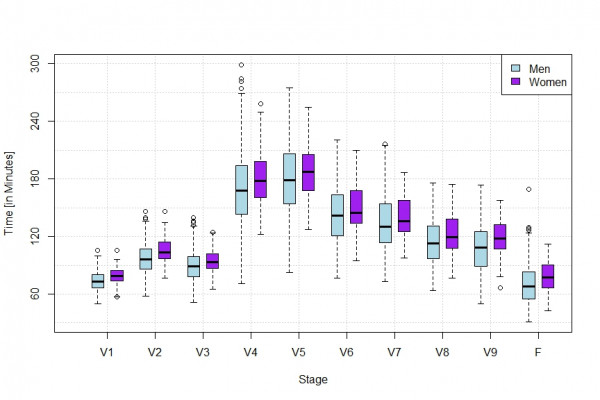
Der Strich innerhalb einer Box markiert den Medianwert, also die Zeit, in der 50% der Teilnehmer den Etappenpunkt erreicht haben. Die Untergrenze bzw. Obergrenze der Box entspricht dem unteren bzw. oberen Quartil, d.h. den Etappenzeiten nach denen die ersten 25% bzw. 75% der Läufer jeweils ankamen. Minimale und maximalen beobachteten Zeiten der jeweiligen Etappe lassen sich durch die einzelnd abgetragenen Punkte bzw. durch die Position der horizontalen Striche an den „Schnurrbarthaaren“ ablesen.
Innerhalb der Box finden sich also insbesondere die Etappenzeiten der mittleren 50% der Läufer.
Wir sehen, dass die weiblichen Teilnehmer zwar generell etwas langsamer als die Gruppe der Männer unterwegs waren, allerdings die langsamste Frau in jeder Etappe immernoch schneller als der jeweils langsamste Mann war. Dabei sind in jeder Etappe das Feld der mittleren 50% der Frauen tendenziell dichter beisammen als dies bei den Männer der Fall ist. Dies sieht man da die Boxen der Frauen für jede Etappe kleiner sind als die Boxen der Männer.
Bis einschließlich V3 liegen die Zeiten der mittleren 50% der Läufer noch eng beisammen; die Boxen sind allgemein relativ klein. Der Weg von V3 nach V4 ist offensichtlich die erste schwierigere Etappe, die Zeiteinläufe der mittleren 50% kläffen bei V4 weit auseinander. Ebenso explodiert die Spannweite, also der Zeitabstand des Etappen-Langsamsten zum Etappenschnellsten.
Erst auf der letzten Etappe, also dem Downhill über den Jägersteig zurück nach Grainau, sind die mittleren 50% der Läufer wieder dichter beisammen.
Stephan Hugenschmidts Dominanz beim Ultratrail
Was die obige Tabelle mit den Ankunftszeiten schon vermuten ließ, das wollen wir in den folgenden Abschnitten einmal etwas genauer unter die Lupe nehmen. Wir wollen die außergewöhnliche Leistung von Stephan Hugenschmidt heraustellen und uns der Klärung der Frage widmen, was einen schnellen Läufer beim Zugspitz Ultratrail 2014 ausgemacht hat.
Die folgende Graphik zeigt die kumulierte Zeiten (in Minuten) aller 680 Teilnehmer über den insgesamt 11 Etappen des Rennens. Die schwarze Linie zeigt dabei den Durchschnittsläufer während Stephans Zeitverlauf in rot dargestellt ist.
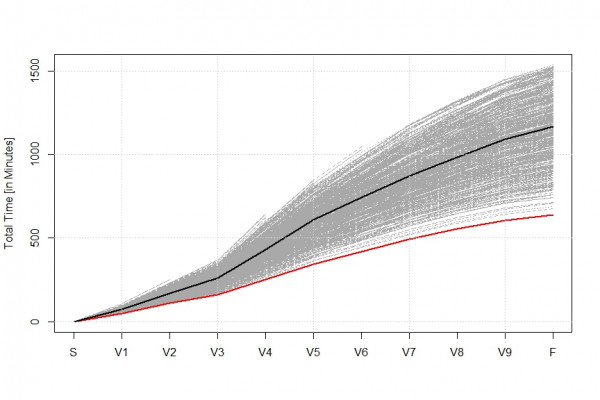
Es ist unschwer zu erkennen, dass Stephan beim diesjährigen Zugspitz Ultratrail außer Konkurrenz lief. Zwar heben sich nachfolgenden Top 4 der Läufer noch deutlich von der breiten Masse ab, aber schon nach 30% der Strecke bestand niemals mehr eine Gefahr für Stephan, der seinen Vorsprung über die Strecke nur weiter auszubauen wußte.
Stephans Dominanz wird noch deutlicher, wenn man die kumulierten Zeiten als Abweichung der Zeiten des Durchschnittlsläufers darstellt:
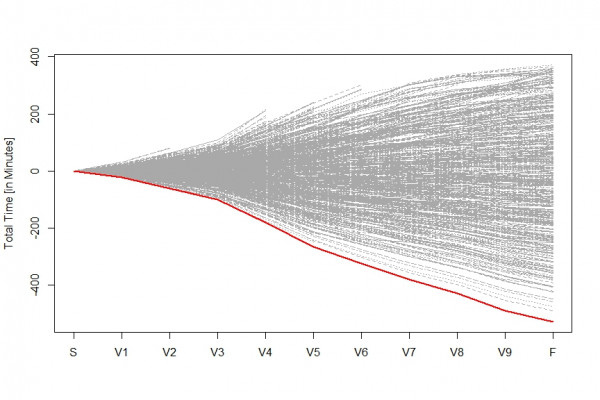
Stephan kam also insgesamt weit über 400 Minuten früher als der durchschnittliche Läufer ins Ziel. Die gute Nachricht für uns: da ist sicherlich noch sehr viel Zeit zur Verbesserung für den durchschnittlichen Breitensportler drin.
Aus den Graphiken wird desweiteren sofort klar, dass die kumulierten Zeiten um die Zeit des durchschnittlichen Läufers schwanken und diese Schwankung von Etappe zu Etappe insgesamt stark zunimmt: ist das Feld zeitmässig auf den ersten Etappen noch sehr dicht beisammen beträgt der Unterschied bei der Zieleinkunft schon gute 800 Minuten.
Was braucht es für einen gute Platzierung beim Zugspitz Ultratrail?
Es stellt sich die Frage, wie und ob man diesen Effekt des zeitlichen Auseinandersklaffens, der wohl vorsätzlich auf Erschöpfung und unterschiedliche Trainingszustände zurückzuführen ist, erklären kann und ob wir damit Rückschlüsse auf eine optimale Strategie für den Zugspitz Ultratrail schließen können: Sollte man versuchen möglichst gleichmässig und schnell durchzukommen? Sollte man lieber anfangs alles geben oder die Strecke doch lieber langsam angehen und sich seine Energie für das Ende hin aufsparen? Sind es vielleicht die flachen Teilstücke wie z.b. das ca. 10 km lange Stück zwischen dem Hubertushof (VP5) und Mittenwald (VP6) bei denen man ein paar Körner mehr auflegen sollte?
Zur Klärung dieser Frage betrachten wir am besten die Einzelzeiten für die Etappen, die in der nachfolgenden Darstellung festgehalten sind:
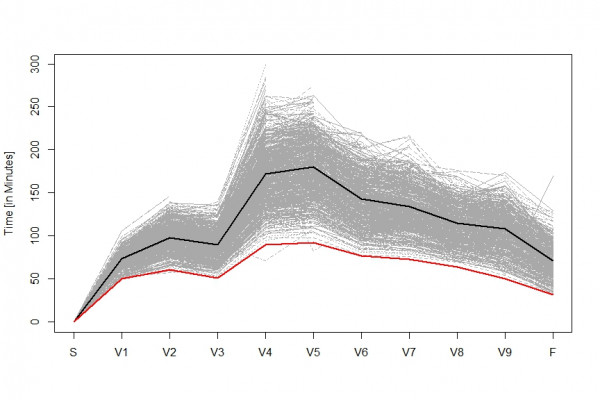
Auch hier sehen wir die Dominanz des Erstplazierten, dessen Zeiten abermals durch die rote Linie kenntlich gemacht wurde. Seine Kurve verläuft weit unterhalb der Kurven der übrigen Teilnehmer. Aber gleichzeitig sehen wir hier auch, dass bezüglich des Streckenrekords noch Luft nach oben ist: in einzelnen Etappen gab es tatsächlich immer wieder Teilnehmer, die schneller als der insgesamt Erstplatzierte waren.
Eine Beschreibung der Daten mit Hilfe funktionaler Datenanalyse
Kurven wie sie in der letzten Abbildung dargestellt sind, sind komplexe Objekte. In der Statistik nutzt man eine sogenannte funktionale Hauptkomponentenanalyse um solch komplexe Objekte besser verstehen und beschreiben zu können. Dazu zerlegt man die Kurven in sogenannte Hauptkomponenten. Jede Hauptkomponente erklärt dabei einen Teil der Variation der Ursprungskurve.
Hier ergibt sich, dass wir bereits insgesamt 95% der gesamten Variation der in der letzten Graphik dargestellten Zeiten mit Hilfe der ersten 4 Hauptkomponenten (Principal Components) erklären können. Dabei erklärt die erste Hauptkomponente alleine bereits 86%, die zweite 5%, die dritte ca. 3% und die vierte 2% der gesamten Variation der dargestellen Kurven.
Für jede inviduelle Kurve, die in obiger Graphik grau dargestellt wird, können wir zu jedem der 4 Hauptkomponenten dann einen zugehörigen Koeffizienten berechnen, die sogenannten Principal Component Scores (PCS). Die Principal Component Scores eines einzelnen Athleten können dann weiter analysiert werden. Durch deren numerischen Werte können Defizite und Stärken eines Athletens herausgearbeitet werden, womit sie zu einem spezifischeren und effizienteren Training beitragen können.
Der Effekt der ersten Hauptkomponente
Schauen wir uns das ganze einmal graphisch an, so sehen wir, dass die erste Hauptkomponente, die den Großteil der Variation in den Ursprungskurven erklärt, im wesentlichen ausschließlich die grundlegende Geschwindigkeit erklärt.
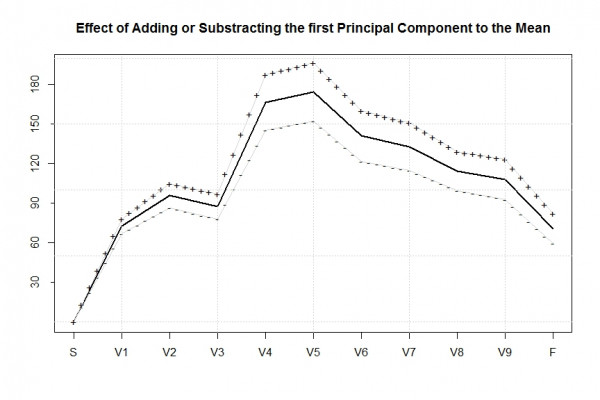
Der jeweilige Effekt der ersten Hauptkpomponente ist im wesentlichen annähernd eine bloße Verschiebung der Kurve der Zeiten des Durchschnittsläufers nach oben oder unten:
Wenn ein Teilnehmer einen positiven Koeffizienten (Principal Component Score, oder nur Score) für die erste Hauptkomponente hat, so braucht er im wesentlichen allgemein etwas langsamer als der durch die schwarze Kurve repräsentierte Druchschnittsläufer. In der Graphik ist der Effekt eines positiven Scores bezüglich der ersten Komponente durch den Verlauf der „+ + +“ Kurve festgehalten.
Hat ein Läufer hingegen einen negativen Koeffizienten für die erste Hauptkomponente, so war seine Grundgeschwindigkeit schneller als die des Durchschnittsläufer. Der Effekt eines negativen Scores bezüglich der Komponente ist durch den Verlauf der „- – -“ Kurve festgehalten.
Es ist wenig überraschend, dass die zugehörigen Scores der top-platzierten Sportler stark negativ waren und die Scores der langsamsten Sportler deutlich positiv waren. Dies lässt sich auch in folgendem Plot festhalten, der die kumulierte Zeit bis zum Finish über den Wert Scores bezüglich der ersten Komponente sämtlicher Finisher darstellt:

Es existiert ein im wesentlichen linearer Zusammenhang zwischen der kumulierten Zeit (und somit der Platzierung) und dem Score der ersten Komponente. Eine Erkenntnis, die jedoch nach der Interpretation der ersten Komponente als Grundgeschwindigkeit wenig überraschend ist.
Der Effekt der zweiten Hauptkomponente
Die zweite Hauptkomponente fasst diejenigen Läufer zusammen, die die Strecke bis zu den ersten 6 Verpflegungspunkten zu schnell angegangen sind und in der zweiten Hälfete des Rennens dafür im Vergleich zum Durchschnittsläufer Einbußungen hinnehmen mussten.
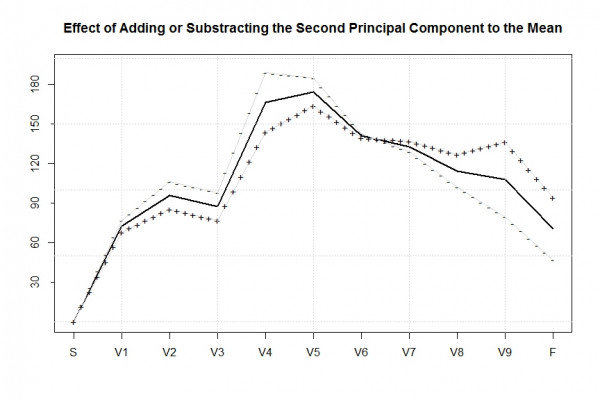
Diese Interpretation ist der Effekt eines positiven Scores bezüglich der zweiten Hauptkomponente (ersichtlich an der „+ + +“ Kurve). Hat ein Teilnehmer hingegen einen negativen Score für die zweite Komponente, so ließ er es bis VP6 im Vergleich zum Durchschnittsläufer eher gemütlich angehen, hatte allerdings danach noch genug Körner um deutlich schneller als der Durchschnittsläufer über den Osterfelderkopf hinauf und anschließend auf dem Jägersteig hinab in Richtung Ziel zu laufen.
Der Effekt der dritten Hauptkomponente
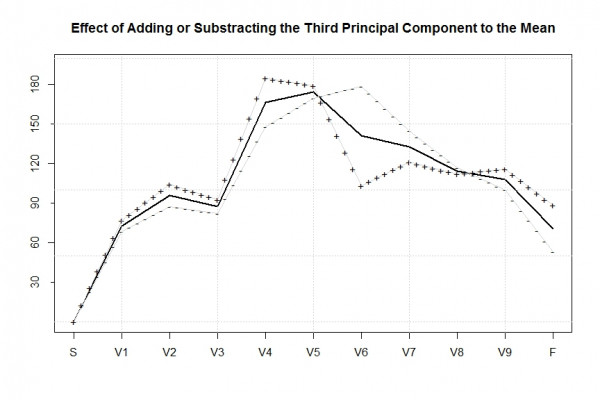
Die dritte Hauptkomponente erklärt primär die Variation des relativ einfachen und annähernd höhenmeterlosen Stücks zwischen der Hubertushütte an VP5 und der Labestation am Ferchensee bei VP7 bevor es danach wieder anstrengend nach oben geht. Jemand der einen positiven Score für diese Komponente hat, kann auch nach 50 km im Flachen noch zügiger geradeaus laufen (ersichtlich durch die „+++“ Kurve, die auf dem betreffenden Streckenstück unterhalb der Durchschnittskurve verläuft). Jemand, der einen negativen Score auf dieser Komponente hat, braucht hingegen ein wenig mehr Zeit als der Durchschnittsläufer auf diesem Streckenabschnitt.
Der Effekt der vierten Hauptkomponente
Die vierte Hauptkomponente beschreibt die Variation des letzte Drittels der Strecke: Das Stück vom Ferchensee über die Alpspitze bis zum Ziel.
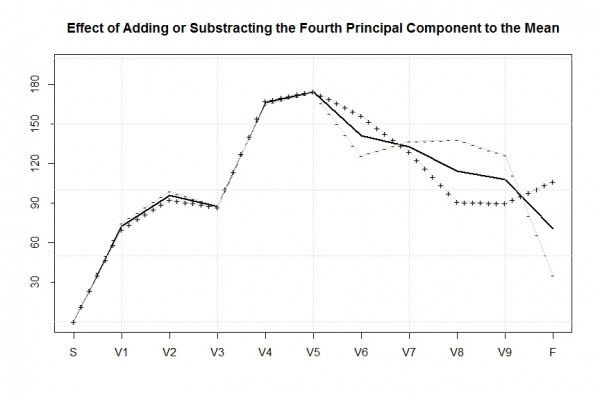
Ein positiver zugehöriger Score bedeutet, dass jemand auf dem Stück schneller als der Durchschnittsläufer berghoch kam, jedoch dann auf dem Jägersteig wieder Zeit verlor. Ein negativer Score deutet hingegen auf einen relativ starken Bergabläufer hin, der zwar auf der Strecke zur Alpspitze hoch ins Stocken kam, jedoch dann auf dem Jägersteig nochmals alles gab.
Die Verteilung der zu den Hauptkomponenten zugehörigen Scores
Nachdem wir nun den Effekt der vier Hauptkomponenten erklärt haben können wir uns nun der Verteilung der zugehörigen Principal Component Scores widmen. Jedem einzelnen Finisher kann nämlich zu jeder der vier Komponenten ein individueller Score zugeordnet werden.
Wie erwähnt könnte man individuelle Scores der vier Komponenten eines einzelnen Athleten nun dazu benutzen um sein Training anzupassen, um dann ganz gezielt individuelle Stärken auf der Strecke weiter auszubauen und gegen Defizite anzukämpfen. Allerdings wollen wir hier versuchen allgemeinere Urteile und Beobachtungen über alle Athleten zu treffen. Dafür schauen wir uns die jeweils 493 Scores aller Finisher an. Die Gesamtheit dieser Scores können wir komponenteweise gegeneinander in einem Streuungsdiagramm darstellen:

Im Streuungsdiagramm werden schnell Zusammenhänge zwischen den 4 Scores sichtbar. Betrachten wir die erste Spalte in der obigen Abbildung, dann ist der Wert des ersten Principal Component Scores den ein einzelner Ultratrailer erreicht hat auf der jeweiligen X-Achse dargestellt. Ein mittlerer Wert von 0 entspricht dem Durchschnittsläufer. Auf der Y-Achse ist jeweils der Wert der übrigen Hauptkomponenten abgetragen.
Ein Beispiel: Im Streuungsdiagramm in Spalte 1, Reihe 2 in der Graphik werden also die individuellen Scores der 2. Komponente über den zugehörigen Scores der ersten Komponente dargestellt. In Spalte 1, Reihe 3 werden die Scores der dritten Komponente über denen der ersten Komponente dargestellt.
Erinnern wir uns, dass die erste Komponente vor allem die Grundschnelligkeit ausdrückte, so ist wenig überraschend, dass Stephan Hugenschmidt für die erste Komponente den kleinsten Score mit einem Wert von ungefähr -60 hatte: ein sehr stark negativer Wert. In den Streuungsdiagrammen der ersten Spalte der Graphik ist seine Leistung jeweils durch den Punkt, der ganz außen links liegt dargestellt.
Wir sehen auch dass die Scores der übrigen Komponenten, die zu diesen Punkt gehören ungefähr den Wert Null haben: Stephans Stärke war es also vor allem grundsätzlich und relativ gleichmäßig einfach sehr viel schneller als der Durchschnitt zu sein ohne dabei großartige Einbußungen in bestimmten Streckenabschnitten zu haben.
Auf die schnelle wird klar, dass er ein hervorragend durchtrainierter Sportler ist. Außerdem können wir festhalten, dass man, um den Zugspitz Ultratrail 2014 zu gewinnen, nicht anders als der Durchschnittsläufer laufen muss, sondern eben nur „ein wenig“ schneller.
Der zweite Punkt der auffällt ist, dass die Streuung der Scores mit dem Wert des ersten Scores wächst: In der ersten Spalte schwanken die übrigen Scores trichterförmig über den Werten der Scores für die erste Komponente.
Außerdem wird ein Ausreisser bezüglich der 4. Komponente sichtbar. Dieser Punkt gehört zum 226. Platzierten (Overall Men), dessen Zeit an der Etappe 9 bis 10 eventuell falsch gemessen wurde. Er benötigte dort auffallend schnelle 0:54.51 Stunden, was der drittbesten Zeit entsprach, brauchte dann jedoch bis zum Finish völlig untypische 2:49.32 Stunden – vielleicht ein Anzeichen auf eine Verletzung?!
Die Scores der Sportler, die einen sehr negativen Score für die erste Komponente erreichten, streut relativ nahe bei Null für jede der anderen Komponenten. Wohingegen die Streuung der übrigen Komponenten für Finisher, die generell etwas langsamer unterwegs waren, sehr groß ist.
Was können wir noch sehen?
Wir sahen bereits, dass der diesjährige Sieger nicht viel anders als der Durchschnittsläufer unterwegs war, sondern im wesentlichen einfach nur „ein wenig“ schneller. Unklar ist jedoch noch was die am Ende des letzten Abschnitts angesprochene Beobachtung bezüglich der trichterförmigen Streuung der Komponenten 2-4 über der ersten Komponente bedeutet, die in den Scatterplots der ersten Spalte (bzw. Reihe) der Scatterplotmatrix ersichtlich ist. Wie angesprochen bedeutet dies, dass die Streuung der Scores der übrigen Komponenten mit dem Wert der ersten Komponente wächst.
Diese Zunahme der Streuung deutet m.E. vor allem auf unterschiedliche Trainingszustände und damit einhergehende individuelle Stärken und Schwächen der Breitensportler hin: Das Teilnehmerfeld ist bunt gemischt und umso langsamer ein Athlet grundsätzlich unterwegs war, desto unterschiedlicher waren seine individuellen Stärken und Schwächen auf den jeweiligen Streckenabschnitten wie sie durch die Komponenten 2-4 beschrieben werden konnten. Hierzu beachte man auch, dass die Plots in Reihe 3 und 4 der zweiten Spalte der letzten Graphik auf einen völlig zufälligen Zusammenhang zwischen der zweiten und dritten und der zweiten und vierten Komponente hindeuten: Die zugehörigen Streuungsdiagramme zeigen einfach nur zufällige Punktewolken ohne erkennbare Systematik.
Sämtliche Top Athleten hatten hingegen, wie weiter oben herausgestellt, einen negativen Score bezüglich der ersten Komponente. Sie waren mit einer schnellen allgemeinen Grundgeschwindigkeit auf der gesamten Strecke unterwegs und gleichzeitig auch homogener bezüglich der Stärken und Schwächen entlang der Teilstrecken: Ihre zugehörigen Scores der übrigen Komponenten schwankten nur sehr gering um 0, wie in der Trichterförmigen Streuung in den Streuungsdiagrammen erkennbar ist.
Wer bei dem Zugspitz Ultratrail also vorne mitspielen will, sollte viel trainieren um ein schnelles Tempo über die gesamte Strecke möglichst homogen aufrechterhalten zu können.
Stellt die ältere Generation beim Zugspitz Ultratrail die schnelleren Ausdauerläufer?
Es heißt ein guter Ausdauerläufer wird man erst im Alter. Beim Zugspitz Ultratrail kann diese Aussage statistische jedoch nicht gestützt werden. Wenn wir die durchschnittlichen Zielzeiten der „Men“ und „Women“ gegen die der „Master Men“ und „Master Women“ testen, so kann die Hypothese, dass diese beiden Zielzeiten identisch seien, gegen die alternative Hypothese, dass die Mastergeneration schneller ist, nicht abgelehnt werden. Die Masterläufer sind beim Zugspitz Ultratrail also nicht signifikant schneller im Ziel als die Jungspunde.
Allerdings kann man einen ähnlichen Test auch auch bezüglich der Scores der ersten Komponente anstelle der Finisherzeiten unternehmen. Dort kommt heraus, dass die Scores der Teilnehmer in der Masterklasse, tatsächlich signifikant kleiner sind als die Scores der ersten Komponente der „Men“ und „Women“. Ein wenig Wahrheit steckt also doch auch für den Zugspitz Ultratrail in der Aussage, dass man ausdauernd erst mit dem Alter wird: Mit dem Alter geht eine durchschnittlich schnellere Grundgeschwindigkeit einher. Allerdings reicht diese beim Zugspitz Ultratrail nicht aus um insgesamt signifikant bessere Zeiten zu erreichen – zu groß sind die durchschnittlichen Unterschiede und Einflüße der übrigen Komponenten für die beiden Gruppen auf das Gesamtergebnis.
Fazit
Wir sehen, dass sich fortgeschrittene Methoden der statistischen Datenanalyse auch sehr gut zur Analyse von größeren Rennveranstaltungen mit dennoch wenig Datenpunkten nutzen und anschaulich interpretieren lassen. Auch wenn diese erste Analyse natürlich noch sehr oberflächlich ist, bietet es sich hier bereits an die Methoden weiterzuentwickeln um individuelle Trainingsprogramme anzupassen. Denn mit Hilfe der Statistik hat man es schwarz auf weiß, wo und an welchen Stellen man gegenüber dem Durchschnittsläufer seine defizite – und somit sein Verbesserungspotential – hat.